
Comment ne pas jeter son application tous les deux ans ?
Retour d’expérience basé sur les bonnes pratiques appliquées à la plateforme web développée chez Bedrock Streaming
Un peu de contexte
Chez Bedrock Streaming de nombreuses équipes développent et maintiennent des applications frontend pour nos clients et utilisateurs. Certaines ne sont pas toute jeune. En effet, l’application sur laquelle je travaille principalement est un site web dont les développements ont commencé en 2014. Je l’ai d’ailleurs déjà évoquée dans différents articles de ce blog.

Vous pourriez vous dire: “Oh les pauvres maintenir une application vieille de presque 10 ans ça doit être un enfer !”
Rassurez-vous, ce n’est pas le cas ! J’ai travaillé sur des projets bien moins vieux mais sur lesquels le développement de nouvelles fonctionnalités était bien plus pénible.
Aujourd’hui le projet reste à jour techniquement, on doit être sur la dernière version de React alors que celui-ci avait commencé sur une version 0.x.x. Dans ce monde des technologies web souvent décrié (ex: les nombreux articles sur la Javascript Fatigue) dont les outils et les pratiques évoluent constamment, conserver un projet “à jour” reste un vrai challenge.
De plus, dans le contexte de ce projet, en presque 10 ans, nous avons connu une centaine de contributeurs. Certains ne sont restés que quelques mois/années. Comment garder au maximum la connaissance sur “Comment on fait les choses et comment ça marche ?” dans un contexte humain si mouvant ?
C’est ce que je vous propose de vous présenter.
Avec l’aide de mes collègues, j’ai rassemblé la liste des bonnes pratiques qui nous permettent encore aujourd’hui de maintenir ce projet en état. Avec Florent Dubost, on s’est souvent dit qu’il serait intéressant de la publier. Nous espèrons que cela vous sera utile.
S’imposer des règles et les automatiser
Un projet qui résiste au temps c’est tout d’abord un ensemble de connaissances qu’on empile les unes sur les autres. C’est en quelque sorte la tour de Kapla que vous assembliez petit en essayant d’aller le plus haut possible. Une base solide sur laquelle on espère pouvoir ajouter le plus possible avant une potentielle chute.
Dès le début d’un projet on est donc amené à prendre des décisions importantes sur “Comment on souhaite faire les choses ?”. On pense par exemple à “Quel format pour nos fichiers ? Comment on nomme telle ou telle chose ?” Écrire une documentation précise de “Comment on fait les choses” pourrait paraitre une bonne idée.
Cependant la documentation c’est cool, mais ça a tendance à périmer très vite. Nos décisions évoluent mais pas la documentation.
“Les temps changent mais pas les README.”
Automatiser la vérification de chacune des règles qu’on s’impose (sur notre codebase ou nos process) est bien plus pérenne. Pour faire simple, on évite dans la mesure du possible de dire “On devrait faire les choses comme cela”, et on préfère “on va coder un truc qui nous le vérifie à notre place”. En plus de ça, coté JS on est vraiment bien équipé avec des outils comme Eslint qui nous permettent d’implémenter nos propres règles.
Le réflexe qu’on essaie donc d’adopter est donc le suivant:
- “On devrait essayer de faire comme cela à présent !”
- “Ok c’est intéressant, mais comment peut-on s’assurer qu’on fasse comme cela automatiquement avec notre CI (Intégration continue) ?”
L’intégration continue d’un projet est la solution parfaite pour ne rien louper sur chacune des Pull Request que nous proposons. Les reviews n’en sont que plus simples car vous n’avez plus à vous soucier de l’ensemble des règles qui sont déjà automatisées. Dans ce modèle, la review sert donc plus au partage de connaissance qu’au flicage de typo et autre non respect des conventions du projet.
Dans ce principe, il faut donc essayer de bannir les règles orales. Le temps des druides est terminé, s’il faut transmettre oralement toutes les bonnes pratiques d’un projet, l’accompagnement de nouveaux développeurs dans votre équipe n’en sera que plus long.

Un projet n’est pas figé. Ces règles évoluent donc avec le temps. On préfèrera alors l’ajout de règles qui possèdent un script qui autofixera toute la codebase intelligemment. De nombreuses règles Eslint le proposent, et cela est vraiment un critère de sélection très important dans nos choix de nouvelles conventions.
eslint --fixUne règle très stricte qui vous obligera à modifier votre code manuellement avant chaque push est pénible à la longue et énervera vos équipes. Alors qu’une règle (même très stricte) qui peut s’autofixer automatiquement au moment du commit ne sera pas perçue comme gênante.
Comment décider d’ajouter de nouvelles règles ?
Cette question peut paraitre épineuse, prenons par exemple le cas des <tab> / <space> dans les fichiers.
Pour cela, on essaie d’éviter les débats sempiternels et on se plie à la tendance et aux règles de la communauté.
Par exemple, notre base de configuration Eslint) est basée sur celle d’Airbnb qui semble avoir un certain succès dans la communauté JS.
Mais si la règle qu’on souhaite s’imposer n’est pas disponible dans Eslint ou d’autres outils, il nous arrive de préférer ne pas suivre la règle plutôt que de se dire “On le fait sans CI qui vérifie”.
La liste presque exhaustive 🤞
- Le format des fichiers est suivi géré par Editorconfig, prettier et Eslint. Nous avons opensourcé notre propre configuration, si jamais celle-ci peut vous être utile.
- Nous utilisons un nommage de commit bien spécifique pour générer nos changelog. Pour s’assurer que les devs le respectent, une simple étape de notre CI le vérifie.
- On ne souhaite pas qu’un dev fasse grossir énormément nos bundles JS en production, c’est pourquoi nous suivons et mesurons leur taille dans la CI. On utilise un outil maison mais on peut vous recommander l’outil BuildTracker.
- La couverture de tests n’est pas un indicateur pour l’équipe, toutes les lignes n’ont pas la même nécessité pour nous d’être testées. Certaines équipes à Bedrock suivent cependant cet indicateur qui a au moins l’intérêt de donner une tendance.
- Nos tests unitaires tournent bien évidemment sur la CI, ceux-ci doivent passer.
- Nos tests fonctionnels (End to end: E2E) tournent sur Chrome Headless, ils doivent être au vert.
- Les logs de nos tests E2E sont récupérés et parsés afin d’éviter l’introduction d’erreur ou de React warning (Le script de parsing est cependant compliqué à maintenir)
- Les tests fonctionnels fonctionnent dans une sandbox où tout le réseau est proxyfié. Nous surveillons que nos tests ne dépendent pas d’une API non mockée qui pourrait ralentir leur exécution.
- Durant les tests E2E nous vérifions qu’aucune requête d’image n’a généré une 404.
- On réalise quelques vérifications d’accessibilité avec Axe durant nos tests E2E.
- On vérifie quelques règles sur le CSS avec Stylelint et bemlinter (on n’utilise plus BEM aujourd’hui mais il reste encore un peu de style géré en SCSS qu’on migre petit à petit en StyledComponent)
- Le projet est un monorepo sur lequel nous essayons de maintenir les mêmes versions de dépendances pour chaque package. Pour cela nous avons développé un outil qui permet de faire cette vérification monorepo-dependencies-check
- On vérifie que notre fichier
yarn.lockn’a pas été modifié par inadvertance ou bien qu’il a été mis à jour par rapport aux modifications dupackage.json. - Terraform est utilisé pour la gestion de nos ressources cloud, nous vérifions que le format des fichiers est correct.
Tester, tester, tester
J’espère qu’en 2021 il n’est plus nécessaire d’expliquer pourquoi tester automatiquement son application est indispensable pour la rendre pérenne. En JS on est plutôt bien équipé en terme d’outils pour tester aujourd’hui. Il reste cependant l’éternelle question:
“Qu’est-ce qu’on veut tester ?”
Globalement si on recherche sur internet cette question, on voit que des besoins différents font émerger des pratiques et des outils de testing bien différents. Ce serait très présomptueux de penser qu’il y a une bonne manière de tester automatiquement son application. C’est pourquoi il est préférable de définir une ou plusieurs stratégies de test qui répondent à des besoins définis et limités.
Nos stratégies de tests reposent sur deux volontés bien distinctes:
- Automatiser la vérification des fonctionnalités proposées aux utilisateurs en se mettant à sa place.
- Nous fournir des solutions efficaces pour specifier la manière dont nous implémentons nos solutions techniques pour nous permettre de les faire évoluer plus facilement.
Pour cela, nous réalisons deux “types de tests” que je propose de vous présenter ici.
Nos tests E2E
On les appelle “tests fonctionels”, ce sont des tests End-to-end (E2E) sur une stack technique très efficace composée de CucumberJS, WebdriverIO avec ChromeHeadless Il s’agit d’une stack technique mise en place au début du projet (à l’époque avec PhantomJS pour les plus anciens d’entre-vous)
Cette stack nous permet d’automatiser le pilotage de tests qui contrôlent un navigateur. Ce navigateur va réaliser des actions qui se rapprochent le plus de celles que nos vrais utilisateurs peuvent faire tout en vérifiant comment le site réagit.
Il y a quelques années, cette stack technique était plutôt compliquée à mettre en place, mais aujourd’hui il est plutôt simple de le faire. Le site qui héberge cet article de blog en est lui-même la preuve. Il ne m’a fallu qu’une dizaine de minutes pour mettre en place cette stack avec le WebdriverIo CLI pour vérifier que mon blog fonctionne comme prévu.
J’ai d’ailleurs récemment publié un article présentant la mise en place de cette stack.
Voici donc un exemple de fichier de test E2E pour vous donner une idée:
Feature: Playground
Background: Playground context
Given I use "playground" test context
Scenario: Check if playground is reachable
When As user "toto@toto.fr" I visit the "playground" page
And I click on "playground trigger"
Then I should see a "visible playground"
And I should see 4 "playground tab" in "playground"
When I click on "playground trigger"
Then I should not see a "visible playground"
# ...Et ça donne ça en local avec mon navigateur Chrome !
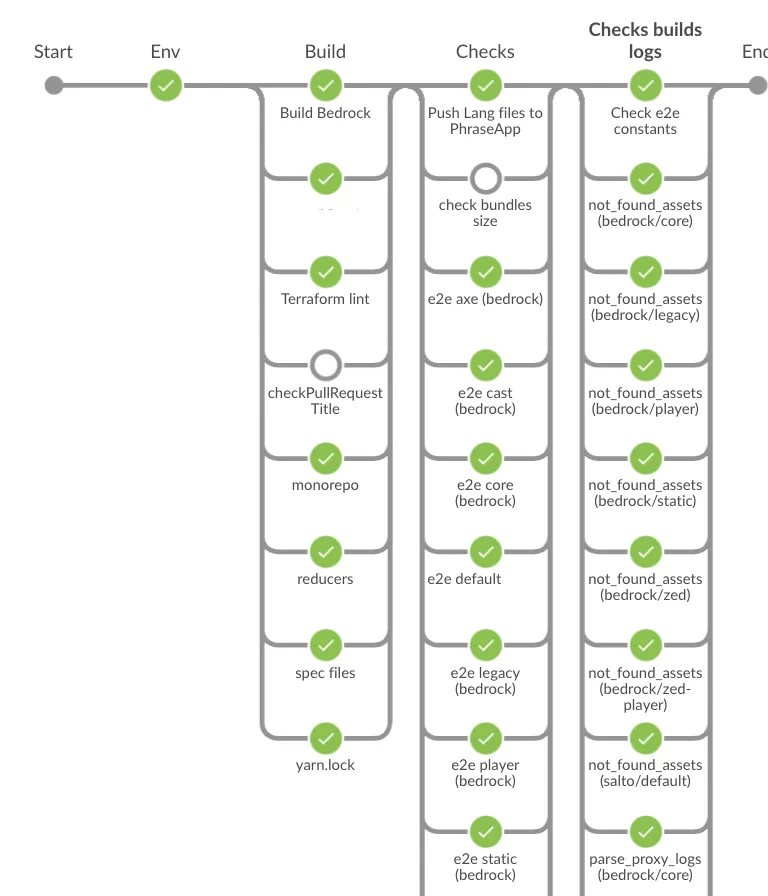
Voilà un schéma qui explique comment cette stack fonctionne:
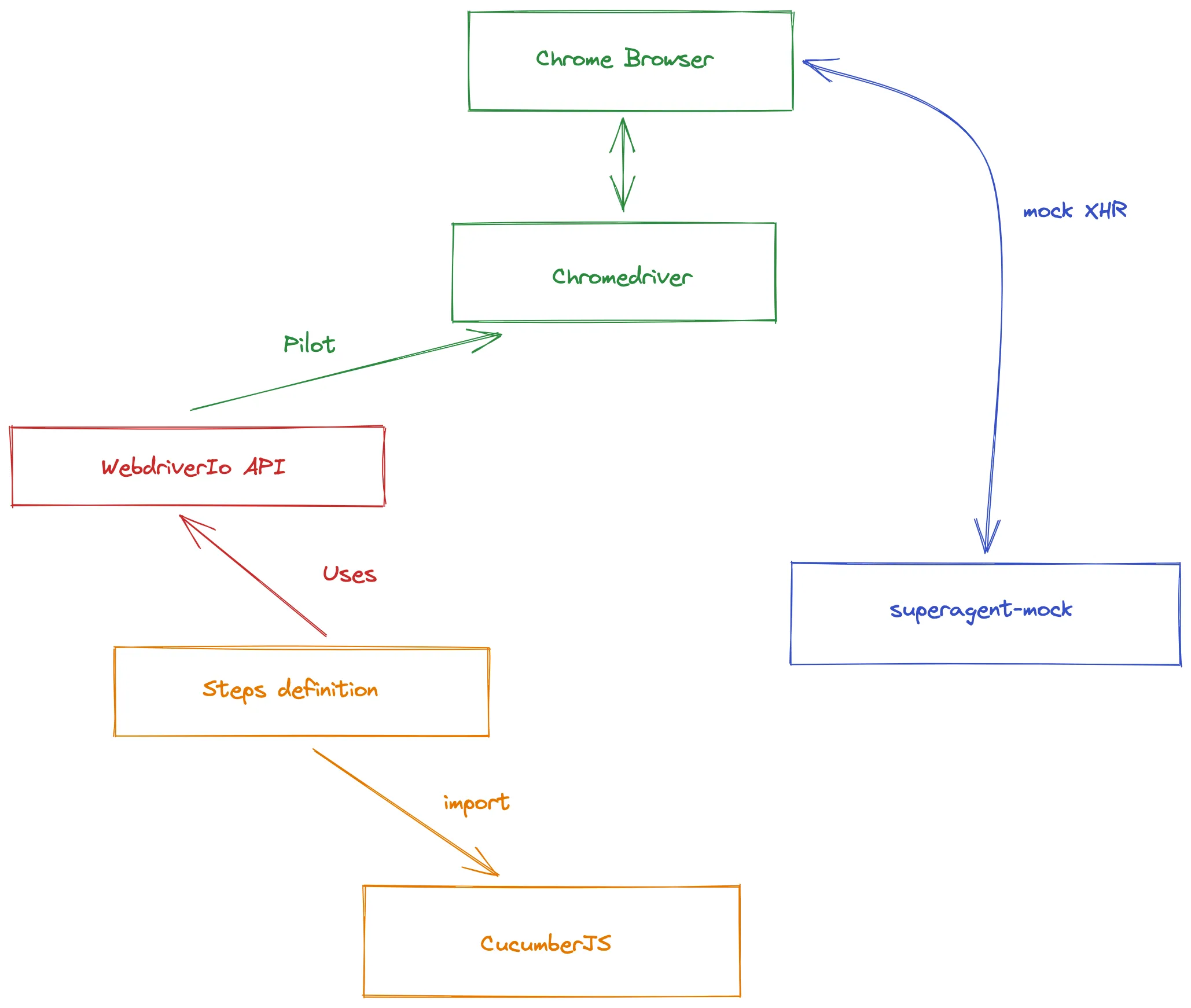
Aujourd’hui, l’application web de Bedrock possède plus de 800 scénarios de tests E2E qui tournent sur chacune de nos Pull Request et sur la branche master.
Ils nous assurent que nous n’introduisons pas de régression fonctionnelle et c’est juste génial !
👍 Les points positifs
- WebdriverIO nous permet également de lancer de manière journalière ces mêmes tests sur des vrais devices en passant par le service payant SAAS Browserstack. On a donc tous les jours un job qui s’assure que notre site fonctionne correctement sur un Chrome dernière version sur Windows 10 et Safari sur MacOs.
- Ces tests nous permettent de facilement documenter les fonctionnalités de l’application grâce au langage Gherkin.
- Ils nous permettent de reproduire des cas qui sont loin d’être nominaux. Dans une logique TDD, ils permettent d’avancer sur le développement sans avoir à cliquer pendant des heures.
- Ces tests nous ont permis de ne pas casser l’ancienne version du site qui est toujours en production pour quelques clients alors que nos efforts se concentrent sur la nouvelle.
- Ils nous apportent une vraie confiance.
- Grâce notre librairie superagent-mock, nous pouvons fixturer (bouchonner, mocker) toutes les API dont on dépend et ainsi même vérifier les cas d’erreurs. De plus, mocker la couche XHR du navigateur permet une amélioration significative du temps d’exécution des tests. 🚀
- Ils nous donne accès à des usages étendus comme :
- vérification de règles d’accessibilité
- check les logs de la console navigateur (pour ne pas introduire d’erreur ou de React Warning par exemple)
- surveiller tous les appels réseaux du site grâce à un proxy
- et j’en passe…
👎 Les complications
- Maintenir cette stack est compliqué et coûteux. Étant donné que peu de ressources sont publiées sur ce domaine, on se retrouve parfois à devoir creuser pendant plusieurs jours pour les réparer 😅. Il nous arrive de nous sentir parfois bien seul à avoir ces soucis.
- Il est très facile de coder un test E2E dit flaky (ie: un test qui peut échouer aléatoirement). Ils nous font croire que quelque chose est cassé. Ils nous prennent parfois du temps à les stabiliser. Il reste cependant bien meilleur de supprimer un test qui ne vous donnera pas un résultat stable.
- Faire tourner tous les tests prend un temps important sur notre intégration continue. Il faut régulièrement travailler sur leur optimisation pour que le feedback qu’ils vous apportent soit le plus rapide possible. Ces temps importants coutent également de l’argent, il faut en effet bien faire tourner ces tests sur des machines. Pour information, l’infrastructure du site web (à lui seul, juste l’hébergement de nos servers Node + fichiers statiques + CDN) coutent bien moins cher que notre intégration continue. Cela fait bien évidemment sourire nos Ops ! 😊
- Les nouvelles recrues de nos équipes n’ont souvent jamais réalisé ce genre de tests, il y a donc une phase
de galèred’apprentissage.. - Certaines fonctionnalités sont parfois trop compliquées à tester avec notre stack E2E (par exemple, les parcours de paiement qui dépendent de tiers). Il nous arrive alors de nous rabattre sur d’autres techniques avec Jest notamment en ayant un scope moins unitaire.
Nos tests “unitaires”
Pour compléter nos tests fonctionnels nous avons également une stack de tests écrits avec Jest. On qualifie ces tests d’unitaires car nous avons comme principe d’essayer de toujours tester nos modules JS en indépendance des autres.
Ne débattons pas ici sur “Est-ce que ce sont des vrais tests unitaires ?”, suffisamment d’articles sur internet traitent de ce sujet.
On utilise ces tests pour différentes raisons qui couvrent des besoins que nos tests fonctionnels ne couvrent pas:
- nous aider à développer nos modules JS avec des pratiques TDD.
- documenter et décrire comment fonctionne un module JS.
- tester des cas limites très/trop compliqués à tester avec nos tests E2E.
- faciliter le refactoring de notre application en nous montrant les impacts techniques de nos modifications.
Avec ces tests, on se met au niveau d’une fonction utilitaire, d’une action Redux, d’un reducer, d’un composant React.
On se base essentiellement sur la fonctionnalité d’automock de Jest qui nous propose d’isoler nos modules JS lorsqu’on teste.
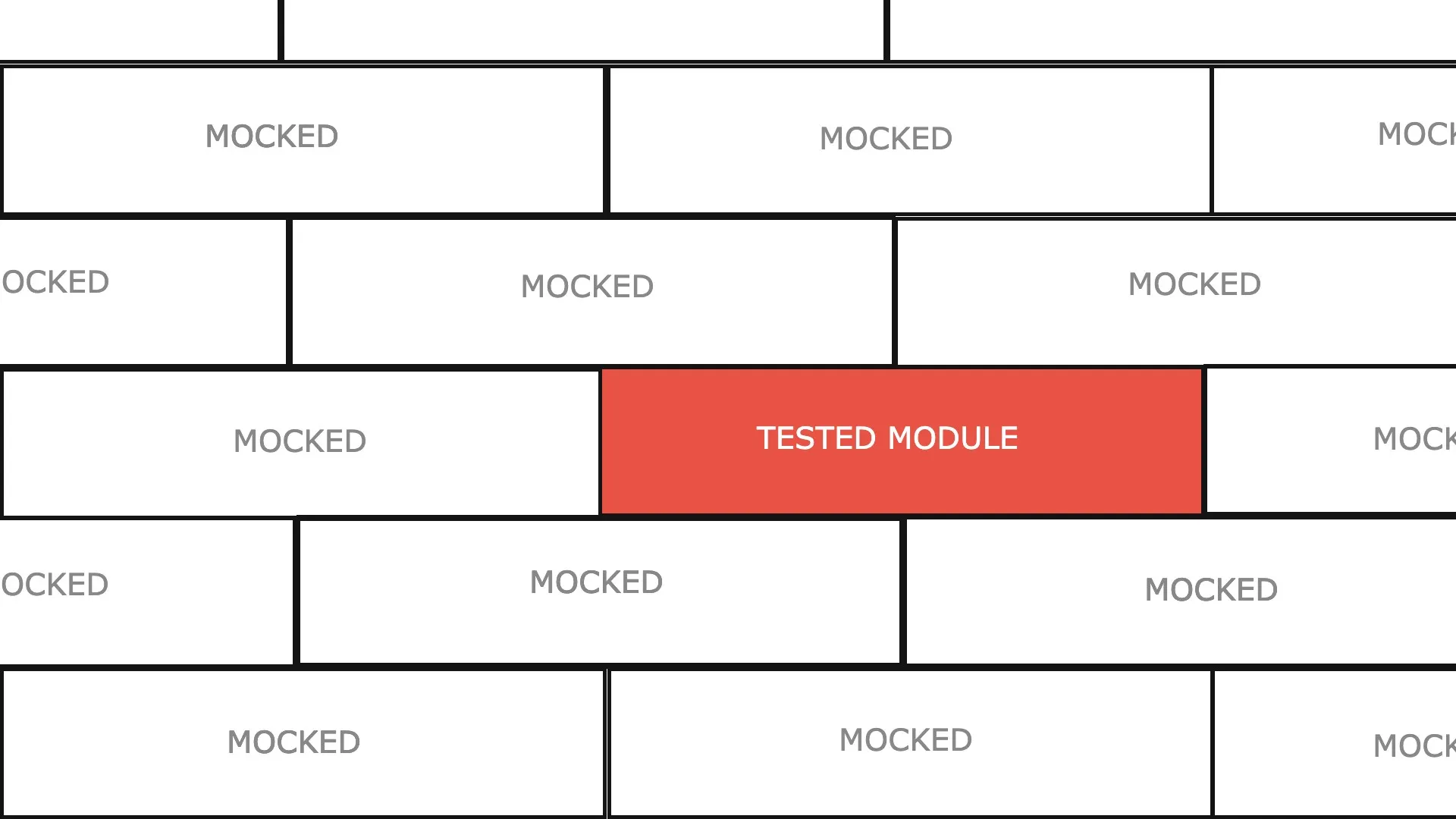
L’image précédente représente la métaphore qui nous permet d’expliquer notre stratégie de tests unitaires aux nouveaux arrivant.
“Il faut s’imaginer que l’application est un mur composé de briques unitaires (nos modules ecmascript), nos tests unitaires doivent tester une à une les briques en indépendance totale des autres. Nos tests fonctionnels sont là pour tester le ciment entre les briques.”
Pour résumer, on pourrait dire que nos tests E2E testent ce que notre application doit faire, et nos tests unitaires s’assurent eux de vérifier comment ça marche.
Aujourd’hui ce sont plus de 6000 tests unitaires qui couvrent l’application et permettent de limiter les régressions.
👍
- Jest est vraiment une librairie géniale, rapide, complète, bien documentée.
- Les tests unitaires nous aident beaucoup à comprendre plusieurs années après comment tout cela fonctionne.
- On arrive toujours à tester unitairement notre code, et cela complète bien nos tests E2E.
- L’
automockest vraiment pratique pour le découpage de tests par modules.
👎
- Parfois, nous nous sommes trouvés limités par notre stack de tests E2E et nous ne pouvions pas uniquement nous baser sur les tests unitaires.
Il nous manquait quelque chose pour pouvoir s’assurer que le ciment entre les briques fonctionnait comme on le souhaitait.
Pour cela, il a été mis en place une deuxième stack de tests Jest nommé “test d’intégration” ou l’
automockest désactivé. - L’abus de Snapshot est dangereux pour la santé. L’usage du “Snapshot testing” peut faire gagner du temps sur l’implémentation de vos tests mais peuvent en réduire la qualité. Avoir à review un object de 50 lignes en Snapshot est ni facile, ni pertinent.
- Avec la dépréciation d’EnzymeJS, nous sommes contraints de migrer sur React Testing Library. Il est bien évidemment possible de tester unitairement des composants avec cette nouvelle librairie. Malheureusement, ce n’est pas vraiment l’esprit et la façon de faire. React Testing Library nous pousse à ne pas jouer avec le shallow rendering.
Nos principes
Nous essayons de toujours respecter les règles suivantes lorsqu’on se pose la question “Dois-je ajouter des tests ?”.
- Si notre Pull Request introduit des nouvelles fonctionnalités utilisateurs, il faut intégrer des scenarios de test E2E. Des tests unitaires avec Jest peuvent les compléter / remplacer en fonction.
- Si notre Pull Request a pour but de corriger un bug, cela signifie qu’il nous manque un cas de test. On doit donc essayer de rajouter un test E2E ou à défaut un test unitaire.
C’est en écrivant ces lignes que je me dis que ces principes pourraient très bien faire l’objet d’une automatisation. 🤣
Le projet reste, les fonctionnalités non
“La seconde évolution d’une fonctionnalité est très souvent sa suppression.”
Par principe, nous souhaitons faire en sorte que chaque nouvelle fonctionnalité de l’application ne base pas son activation sur le simple fait d’être dans la codebase. Classiquement, le cycle de vie d’une “feature” dans un projet peut être le suivant (dans un Github Flow):
- une personne implémente sur une branche
- la fonctionnalité est mergée sur master
- elle est déployée en production
- vis sa vie de fonctionnalité (avec parfois des bugs et des correctifs)
- la fonctionnalité n’est plus nécessaire
- une personne détricote le code et l’enlève
- nouveau déploiement
Pour simplifier certaines étapes, il a été mis en place du feature flipping sur le projet.
Comment ça marche ?
Dans notre config il y a une map clé/valeur qui liste toutes les fonctionnalités de l’application associées à leur statut d’activation.
const featureFlipping = {
myAwesomeFeature: false,
anotherOne: true,
};Dans notre code, nous avons donc implémenté des traitements conditionnels qui disent “Si cette feature est activée alors…”. Cela peut changer le rendu d’un composant, changer l’implémentation d’une action Redux ou bien désactiver une route de notre react-router.
Mais à quoi ça sert ?
- On peut développer des nouvelles évolutions progressivement en les cachant derrière une clé de configuration. On livre des fonctionnalités en production sans les activer.
- En environnement de test, on peut surcharger cette config pour tester des features qui ne sont pas encore activées en production.
- Dans le cas d’un site en marque blanche, on peut proposer ces fonctionnalités à nos clients comme des options possibles.
- Avant de supprimer le code d’une feature, on la désactive puis on fait le ménage sans risque.
- Grâce à un outil maison nommé l’Applaunch, cette config de feature flipping est surchargeable dans une interface graphique à chaud sans déploiement. Cela nous permet d’activer des fonctionnalités sans faire de mise en production du code. En cas d’incident, on peut désactiver des fonctionnalités qui sont dégradées.
Pour vous donner un exemple plus concret, entre 2018 et 2020 nous avons complètement refondu l’interface de l’application. Cette évolution graphique n’était qu’une clé de featureFlipping. La refonte graphique n’a donc pas été la remise à zéro du projet, on continue encore aujourd’hui de vivre avec les deux versions (tant que la bascule de tous nos clients n’est pas terminée).
L’A/B testing
Grâce au super travail des équipes backend et data, on a pu même étendre l’usage du feature flipping en rendant cette configuration modifiable pour des sous groupes d’utilisateurs.
Cela permet de déployer des nouvelles fonctionnalités sur une portion plus réduite des utilisateurs afin de comparer nos KPI.
Prise de décision, amélioration des performances techniques ou produit, expérimentations, les possibilités sont nombreuses et nous les exploitons de plus en plus.
Le futur flipping
Sur une idée originale de Florent Lepretre.
Nous avions régulièrement le besoin d’activer des feature à des heures très trop matinales dans le futur.
Pour cela nous devions être connecté à une heure précise sur notre poste pour modifier la configuration à chaud.
Afin d’éviter d’oublier de le faire, ou de le faire en retard, nous avons fait en sorte qu’une clé de configuration puisse être activée à partir d’une certaine date. Pour cela, nous avons fait évoluer notre selector redux qui indiquait si une feature était activée pour qu’il puisse gérer des formats de date et les comparer à l’heure courante.
const featureFlipping = {
myAwesomeFeature: {
offpubDatetime: "2021-07-12 20:30:00",
onpubDatetime: "2021-07-12 19:30:00",
},
};De nombreux cafés ☕️ à 9h ont été sauvés grâce au futur flipping
Monitorer, Mesurer, Alerter
Pour maintenir un projet aussi longtemps que l’application web de bedrock, des tests, de la documentation et de la rigueur ne suffisent pas. Il faut également de la visibilité sur ce qui marche en production.
“Comment sais-tu que l’application que tu as en production en ce moment même fonctionne comme prévu ?”
On part du principe qu’aucune fonctionnalité ne marche tant qu’elle n’est pas monitorée. Aujourd’hui le monitoring à Bedrock coté Frontend se matérialise par différents outils et différentes stacks. Je pourrais vous citer NewRelic, un Statsd, une stack ELK ou bien encore Youbora pour la vidéo.
Pour vous donner un exemple, à chaque fois qu’un utilisateur commence une session de navigation on envoie un Hit de monitoring anonyme pour incrémenter un compteur dans Statsd. On a alors plus qu’à définir un dashboard qui affiche dans un graphique l’évolution de ce nombre. Si on observe une variation trop importante, cela peut nous permettre de détecter un incident.
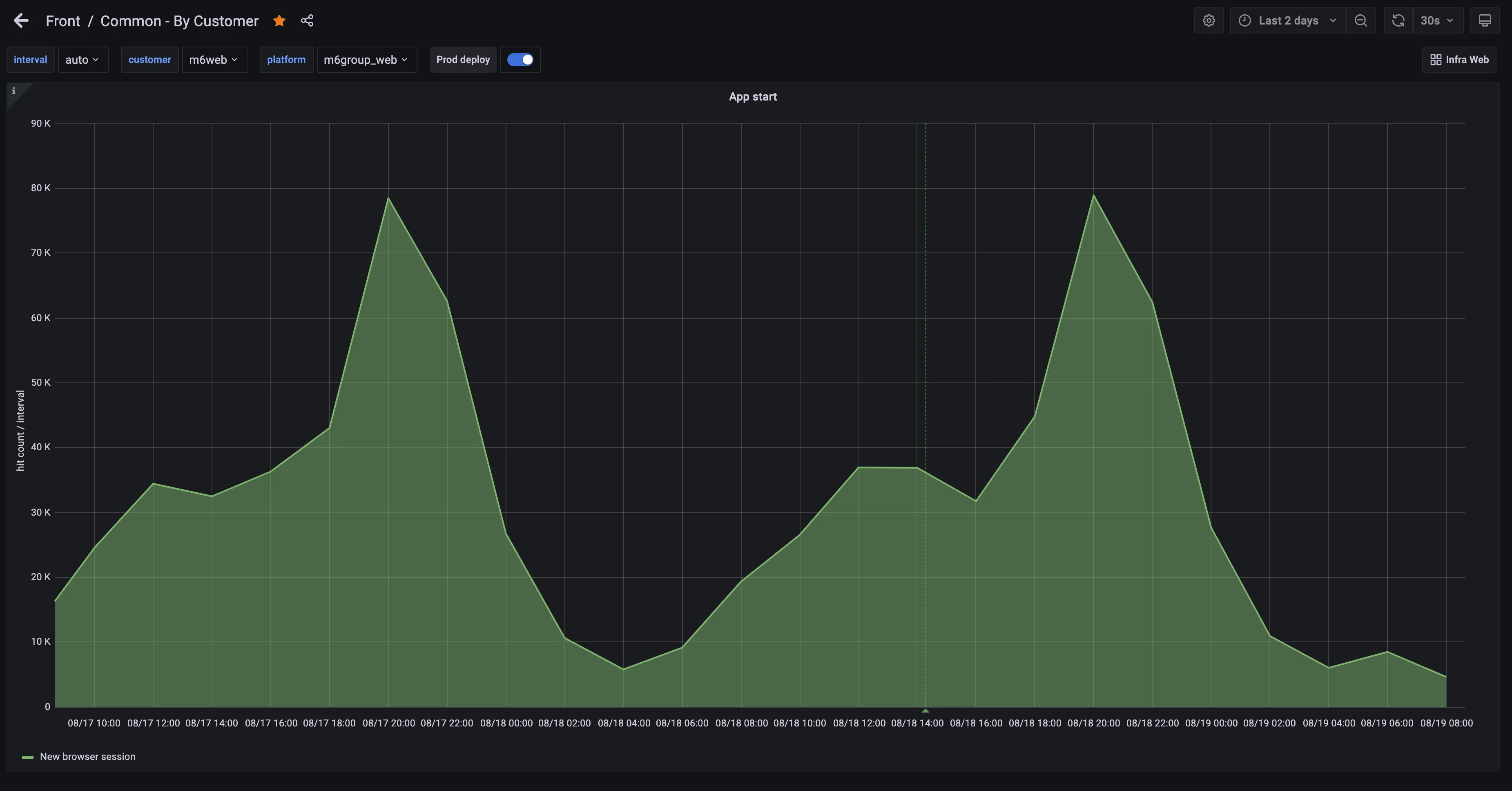
Le monitoring nous offre aussi des solutions pour comprendre et analyser un bug qui s’est produit dans le passé. Comprendre un incident, l’expliquer, en trouver sa root cause sont les possibilités qui s’offrent à vous si vous monitorez votre application. Le monitoring peut également permettre de mieux communiquer avec les clients sur les impacts d’un incident et également d’estimer le nombre d’utilisateurs impactés.
Avec la multiplication de nos clients, bien monitorer nos plateformes n’est plus suffisant. Trop de données, trop de dashboards à surveiller, il devient très facile de louper quelque chose. Nous avons donc commencé à compléter notre suivi des mesures par de l’alerting automatique. Une fois que les mesures nous apportent suffisamment de confiance, on peut facilement mettre en place des alertes qui vont nous prévenir en cas de valeur incohérente.
Nous essayons cependant de toujours déclencher des alertes uniquement quand celle-ci est actionnable. Dans d’autres termes, si une alerte sonne, nous avons quelque chose à faire. Faire sonner des alertes qui ne nécessitent aucune action immédiate humaine génèrent du bruit et de la perte de temps.

Limiter, surveiller et mettre à jour ses dépendances
Ce qui périme plus vite que votre ombre dans un projet web basé sur des technologies javascript, ce sont vos dépendances. L’écosystème évolue rapidement et vos dépendances peuvent vite se retrouver non maintenues, plus à la mode ou bien complètement refondues avec de gros breaking changes.
On essaye donc dans la mesure du possible de limiter nos dépendances et d’éviter d’en ajouter inutilement. Une dépendance, c’est souvent très facile à ajouter mais elle peut devenir un vrai casse-tête à enlever.
Les librairies de composants graphiques (exemple React bootstrap, Material Design) sont un bel exemple de dépendance que nous tenons à ne pas introduire. Elles peuvent faciliter l’intégration dans un premier temps mais celles-ci bloquent souvent la version de votre librairie de composant par la suite. Vous ne voulez pas figer la version de React dans votre application pour deux composants de formulaires.
La surveillance fait aussi partie de nos routines de gestion de nos dépendances.
Depuis l’ajout du signalement de failles de sécurité dans un package NPM, il est possible de savoir si un projet intègre une dépendance qui contient une faille de sécurité connue par une simple commande.
Nous avons donc des jobs journaliers sur nos projets qui lancent la commande yarn audit afin de nous forcer à appliquer les correctifs.
La maintenance de dépendances est grandement facilité par notre stack de tests E2E qui sonnent direcement si la montée de version génère une regression.
Aujourd’hui, hors failles de sécurité, nous mettons à jour nos dépendances “quand on a le temps”, souvent en fin de sprint.
Cela ne nous satisfait pas car certaines dépendances peuvent se retrouver oubliées.
J’ai personnellement l’habitude d’utiliser des outils comme yarn outdated et Dependabot sur mes projets personels pour automatiser la mise à jour de mes dépendances.
Accepter sa dette technique
Un projet accumulera toujours de la dette technique. C’est un fait. Que ce soit de la dette volontaire ou involontaire, un projet qui résiste aux années va forcément accumuler de la dette. D’autant plus, si pendant toutes ces années vous continuez d’ajouter des fonctionnalités.
Depuis 2014, nos bonnes pratiques, nos façons de faire ont bien évolué. Parfois nous avons décidé ces changements mais parfois nous les avons subi (un exemple, l’arrivée des composants fonctionnels avec React et l’api des Hooks).
Notre projet n’est pas complètement “state of art” et on l’assume.

Nous essayons de prioriser nos sujets de refactoring sur les parties de l’application sur lequel on a le plus de souci, le plus de peine. On considère qu’une partie de l’application qui ne nous plaît pas mais sur laquelle on n’a pas besoin de travailler (apporter des évolutions) ne mérite pas qu’on la refactorise.
Je pourrais vous citer de nombreuses fonctionnalités de notre application qui n’ont pas évolué fonctionnellement depuis plusieurs années. Mais comme nous avons couvert ces fonctionnalités de tests E2E depuis le début, nous n’avons pas vraiment eu à y retoucher.
Comme dit plus haut, la prochaine évolution d’une feature de code est parfois sa désactivation. Alors pourquoi passer son temps à ré-écrire toute l’application ?
- Le code devient dans tous les cas du “legacy”.
- Tant que les fonctionnalités sont testées, rien ne nous oblige à tout refactorer en permanence pour que toute notre codebase soit state of art.
- On se focalise sur nos pain points, on re-factorise ce qu’on a vraiment besoin de faire évoluer.
Pour résumer
Les bonnes pratiques présentées ici restent bien évidemment subjectives et ne s’appliqueront pas parfaitement/directement dans vos contextes. Je suis cependant convaincu qu’elles peuvent probablement vous aider à identifier ce qui peut faire passer votre projet de fun à périmé. À Bedrock nous avons mis en place d’autres pratiques que je n’ai pas listées ici mais ce sera l’occasion de faire un nouvel article un jour.
Enfin, si vous souhaitez que je revienne plus en détail sur certains chapitres présentés ici, n’hésitez pas à me le dire, je pourrais essayer d’y dédier un article spécifique.